使用 Docker 和 Kubernetes 将 MongoDB 作为微服务运行

介绍
想在笔记本电脑上尝试 MongoDB?只需执行一个命令,你就会有一个轻量级的、独立的沙箱。完成后可以删除你所做的所有痕迹。
想在多个环境中使用相同的 程序栈 副本?构建你自己的容器镜像,让你的开发、测试、运维和支持团队使用相同的环境克隆。
容器正在彻底改变整个软件生命周期:从最早的技术性实验和概念证明,贯穿了开发、测试、部署和支持。
编排工具用来管理如何创建、升级多个容器,并使之高可用。编排还控制容器如何连接,以从多个微服务容器构建复杂的应用程序。
丰富的功能、简单的工具和强大的 API 使容器和编排功能成为 DevOps 团队的首选,将其集成到连续集成(CI) 和连续交付 (CD) 的工作流程中。
这篇文章探讨了在容器中运行和编排 MongoDB 时遇到的额外挑战,并说明了如何克服这些挑战。
MongoDB 的注意事项
使用容器和编排运行 MongoDB 有一些额外的注意事项:
- MongoDB 数据库节点是有状态的。如果容器发生故障并被重新编排,数据则会丢失(能够从副本集的其他节点恢复,但这需要时间),这是不合需要的。为了解决这个问题,可以使用诸如 Kubernetes 中的 数据卷 抽象等功能来将容器中临时的 MongoDB 数据目录映射到持久位置,以便数据在容器故障和重新编排过程中存留。
- 一个副本集中的 MongoDB 数据库节点必须能够相互通信 - 包括重新编排后。副本集中的所有节点必须知道其所有对等节点的地址,但是当重新编排容器时,可能会使用不同的 IP 地址重新启动。例如,Kubernetes Pod 中的所有容器共享一个 IP 地址,当重新编排 pod 时,IP 地址会发生变化。使用 Kubernetes,可以通过将 Kubernetes 服务与每个 MongoDB 节点相关联来处理,该节点使用 Kubernetes DNS 服务提供“主机名”,以保持服务在重新编排中保持不变。
- 一旦每个单独的 MongoDB 节点运行起来(每个都在自己的容器中),则必须初始化副本集,并添加每个节点到其中。这可能需要在编排工具之外提供一些额外的处理。具体来说,必须使用目标副本集中的一个 MongoDB 节点来执行
rs.initiate和rs.add命令。 - 如果编排框架提供了容器的自动化重新编排(如 Kubernetes),那么这将增加 MongoDB 的弹性,因为这可以自动重新创建失败的副本集成员,从而在没有人为干预的情况下恢复完全的冗余级别。
- 应该注意的是,虽然编排框架可能监控容器的状态,但是不太可能监视容器内运行的应用程序或备份其数据。这意味着使用 MongoDB Enterprise Advanced 和 MongoDB Professional 中包含的 MongoDB Cloud Manager 等强大的监控和备份解决方案非常重要。可以考虑创建自己的镜像,其中包含你首选的 MongoDB 版本和 MongoDB Automation Agent。
使用 Docker 和 Kubernetes 实现 MongoDB 副本集
如上节所述,分布式数据库(如 MongoDB)在使用编排框架(如 Kubernetes)进行部署时,需要稍加注意。本节将介绍详细介绍如何实现。
我们首先在单个 Kubernetes 集群中创建整个 MongoDB 副本集(通常在一个数据中心内,这显然不能提供地理冗余)。实际上,很少有必要改变成跨多个集群运行,这些步骤将在后面描述。
副本集的每个成员将作为自己的 pod 运行,并提供一个公开 IP 地址和端口的服务。这个“固定”的 IP 地址非常重要,因为外部应用程序和其他副本集成员都可以依赖于它在重新编排 pod 的情况下保持不变。
下图说明了其中一个 pod 以及相关的复制控制器和服务。
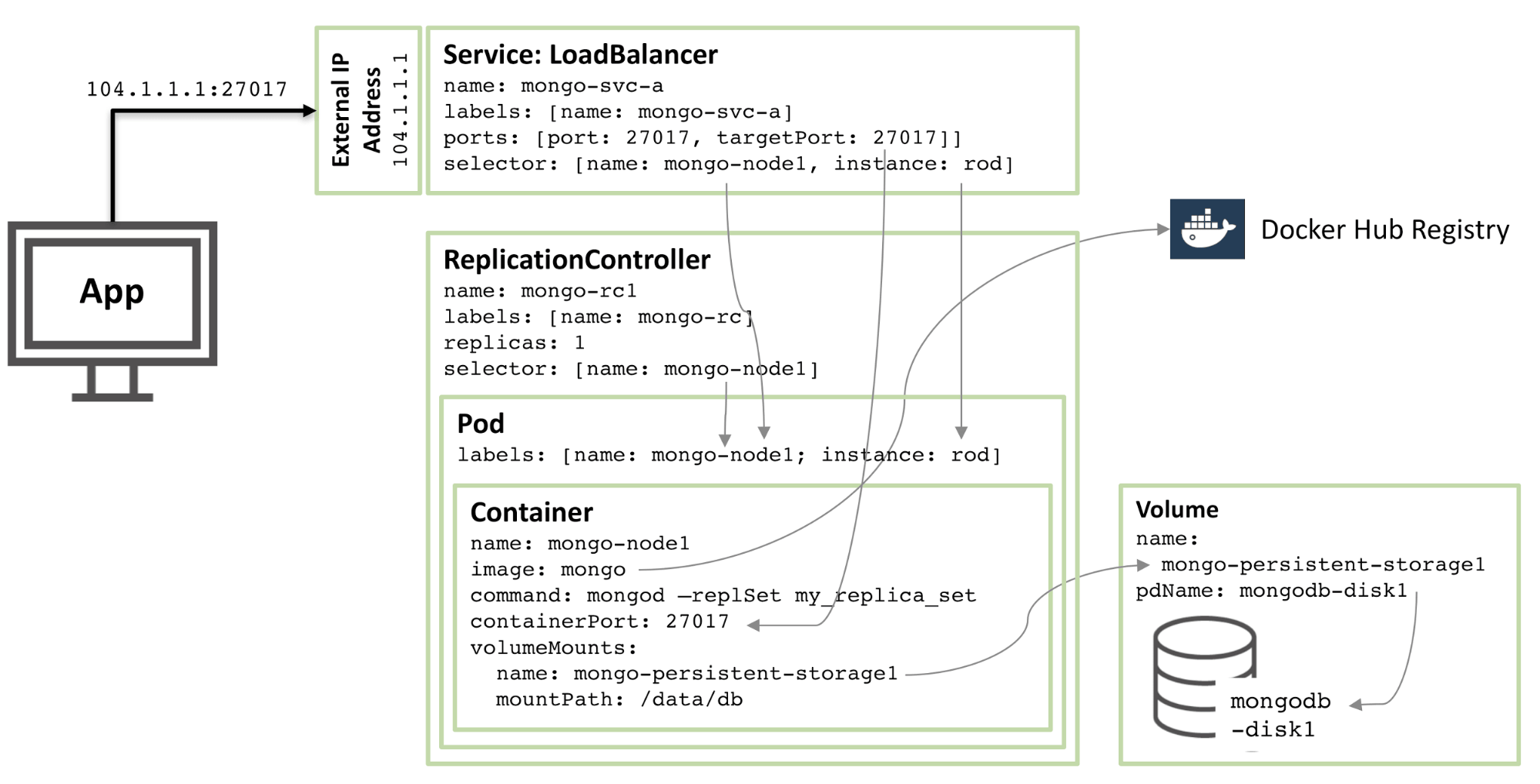
图 1:MongoDB 副本集成员被配置为 Kubernetes Pod 并作为服务公开
逐步介绍该配置中描述的资源:
- 从核心开始,有一个名为
mongo-node1的容器。mongo-node1包含一个名为mongo的镜像,这是一个在 Docker Hub 上托管的一个公开可用的 MongoDB 容器镜像。容器在集群中暴露端口27107。 - Kubernetes 的数据卷功能用于将连接器中的
/data/db目录映射到名为mongo-persistent-storage1的永久存储上,这又被映射到在 Google Cloud 中创建的名为mongodb-disk1的磁盘中。这是 MongoDB 存储其数据的地方,这样它可以在容器重新编排后保留。 - 容器保存在一个 pod 中,该 pod 中有标签命名为
mongo-node,并提供一个名为rod的(任意)示例。 - 配置
mongo-node1复制控制器以确保mongo-node1pod 的单个实例始终运行。 - 名为
mongo-svc-a的负载均衡服务给外部开放了一个 IP 地址以及27017端口,它被映射到容器相同的端口号上。该服务使用选择器来匹配 pod 标签来确定正确的 pod。外部 IP 地址和端口将用于应用程序以及副本集成员之间的通信。每个容器也有本地 IP 地址,但是当容器移动或重新启动时,这些 IP 地址会变化,因此不会用于副本集。
下一个图显示了副本集的第二个成员的配置。
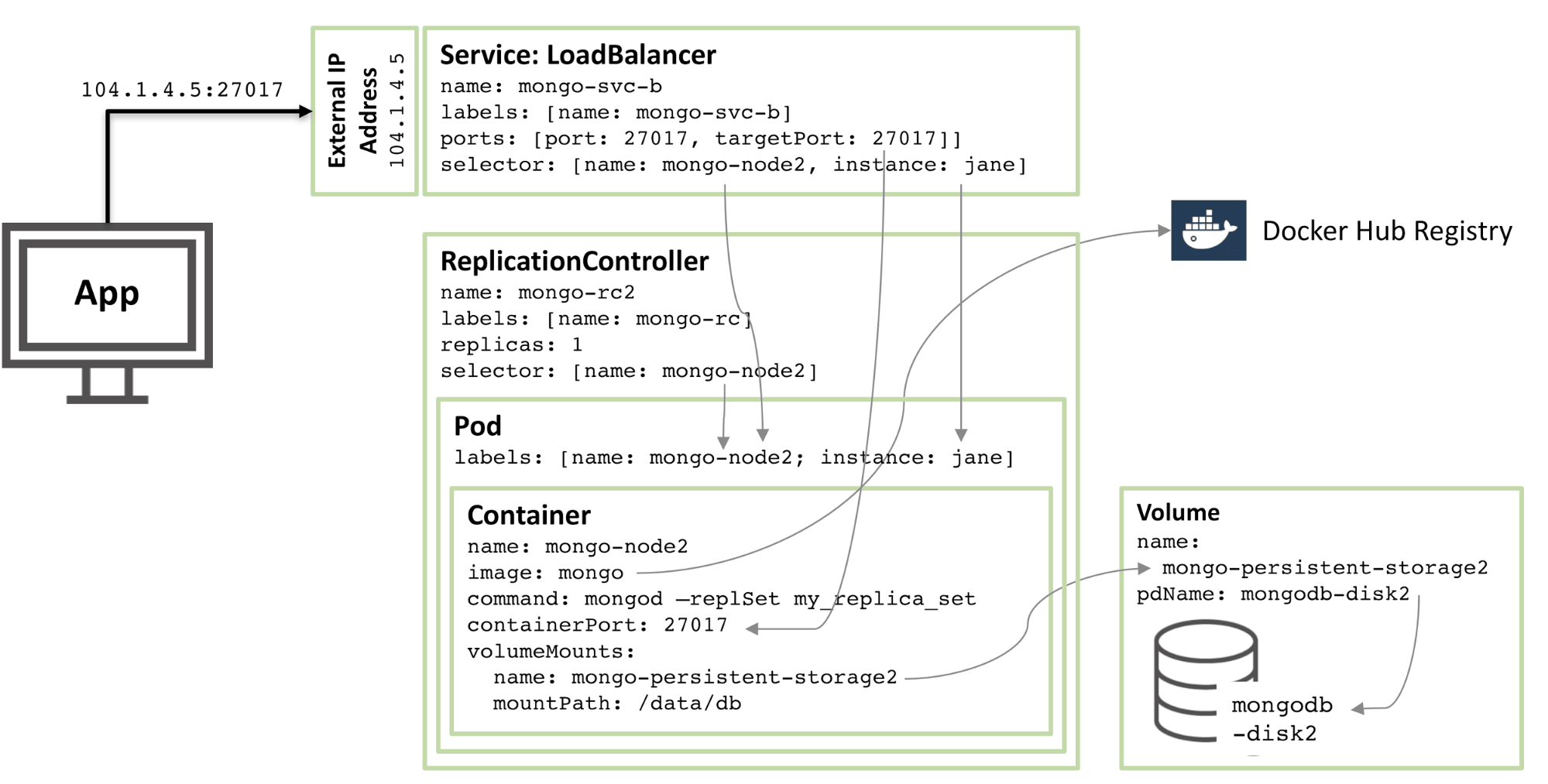
图 2:第二个 MongoDB 副本集成员配置为 Kubernetes Pod
90% 的配置是一样的,只有这些变化:
- 磁盘和卷名必须是唯一的,因此使用的是
mongodb-disk2和mongo-persistent-storage2 - Pod 被分配了一个
instance: jane和name: mongo-node2的标签,以便新的服务可以使用选择器与图 1 所示的rodPod 相区分。 - 复制控制器命名为
mongo-rc2 - 该服务名为
mongo-svc-b,并获得了一个唯一的外部 IP 地址(在这种情况下,Kubernetes 分配了104.1.4.5)
第三个副本成员的配置遵循相同的模式,下图展示了完整的副本集:
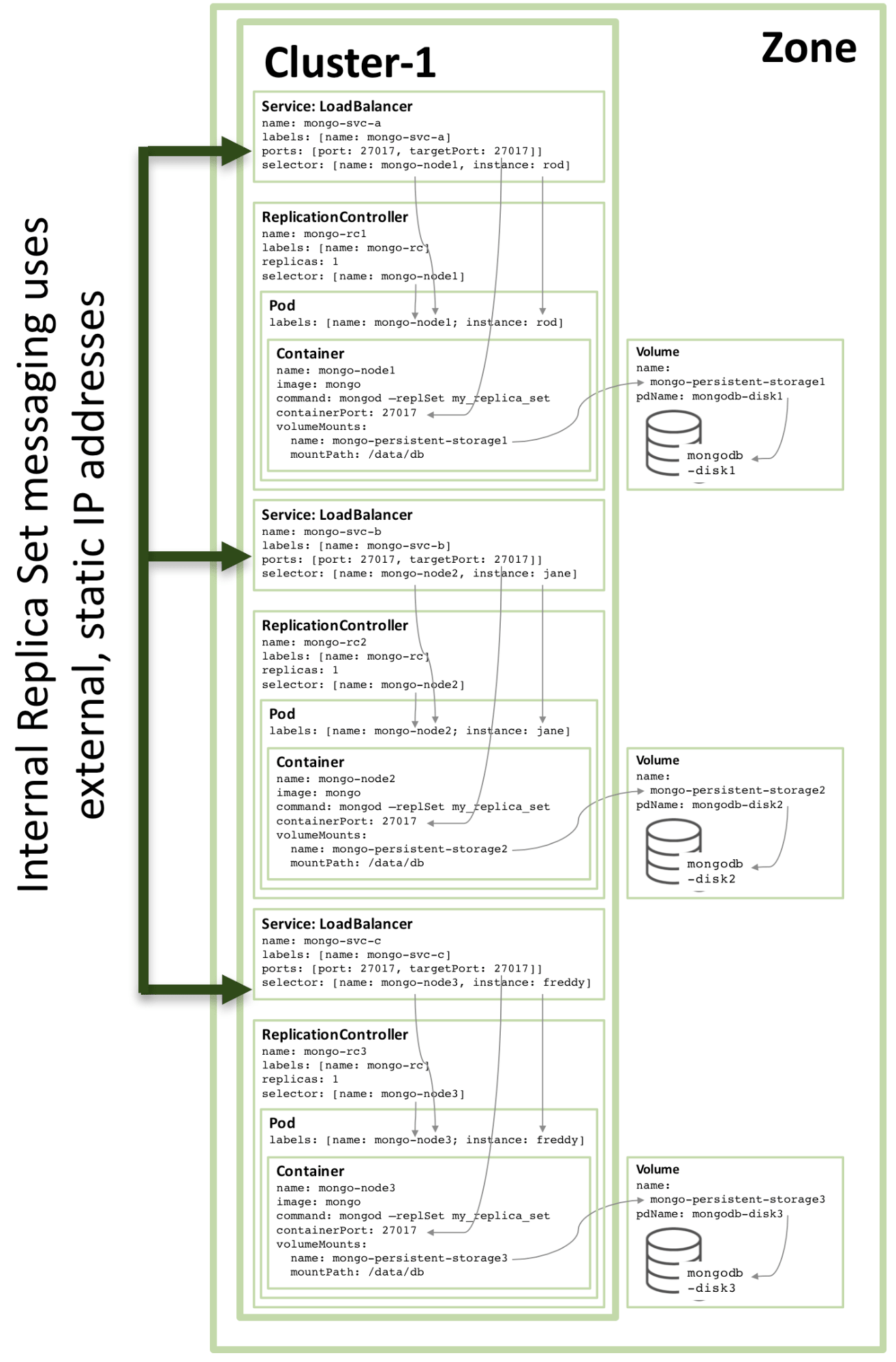
图 3:配置为 Kubernetes 服务的完整副本集成员
请注意,即使在三个或更多节点的 Kubernetes 群集上运行图 3 所示的配置,Kubernetes 可能(并且经常会)在同一主机上编排两个或多个 MongoDB 副本集成员。这是因为 Kubernetes 将三个 pod 视为属于三个独立的服务。
为了在区域内增加冗余,可以创建一个附加的 headless 服务。新服务不向外界提供任何功能(甚至不会有 IP 地址),但是它可以让 Kubernetes 通知三个 MongoDB pod 形成一个服务,所以 Kubernetes 会尝试在不同的节点上编排它们。
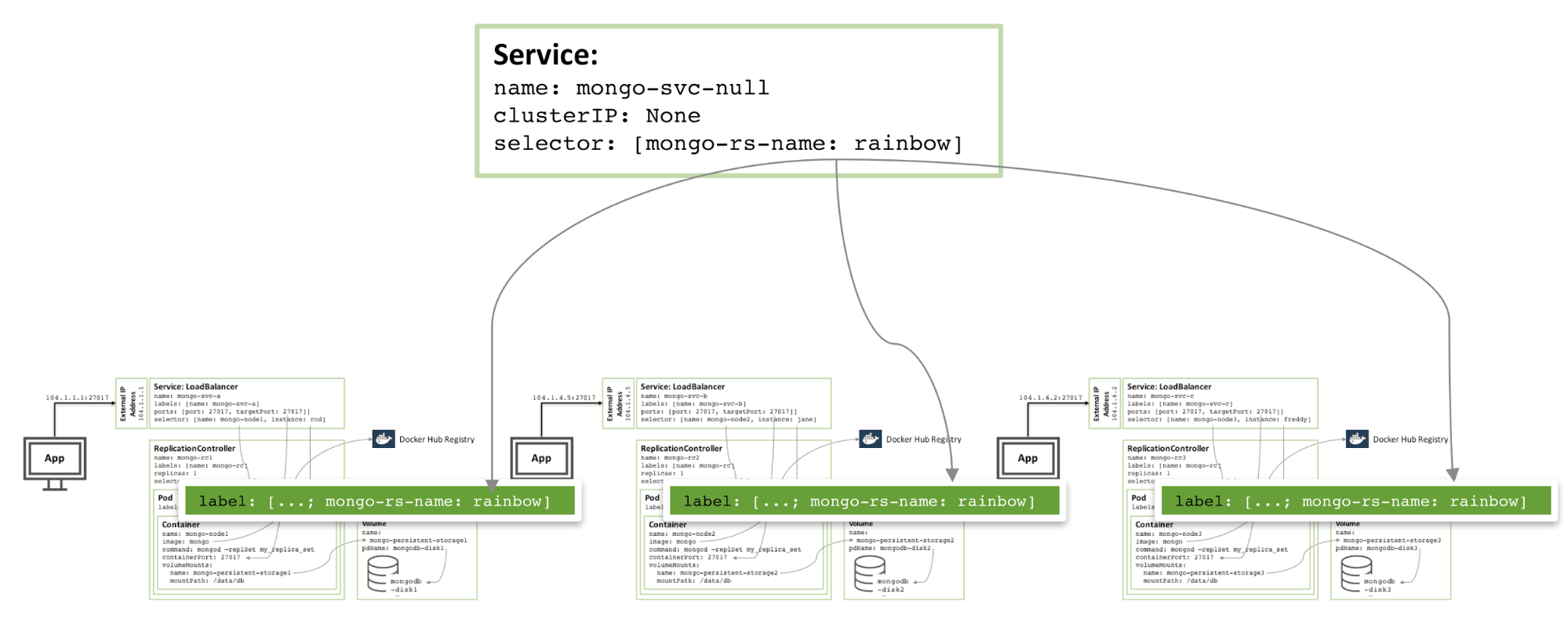
图 4:避免同一 MongoDB 副本集成员的 Headless 服务
配置和启动 MongoDB 副本集所需的实际配置文件和命令可以在白皮书《启用微服务:阐述容器和编排》中找到。特别的是,需要一些本文中描述的特殊步骤来将三个 MongoDB 实例组合成具备功能的、健壮的副本集。
多个可用区 MongoDB 副本集
上面创建的副本集存在风险,因为所有内容都在相同的 GCE 集群中运行,因此都在相同的 可用区 中。如果有一个重大事件使可用区离线,那么 MongoDB 副本集将不可用。如果需要地理冗余,则三个 pod 应该在三个不同的可用区或地区中运行。
令人惊奇的是,为了创建在三个区域之间分割的类似的副本集(需要三个集群),几乎不需要改变。每个集群都需要自己的 Kubernetes YAML 文件,该文件仅为该副本集中的一个成员定义了 pod、复制控制器和服务。那么为每个区域创建一个集群,永久存储和 MongoDB 节点是一件很简单的事情。
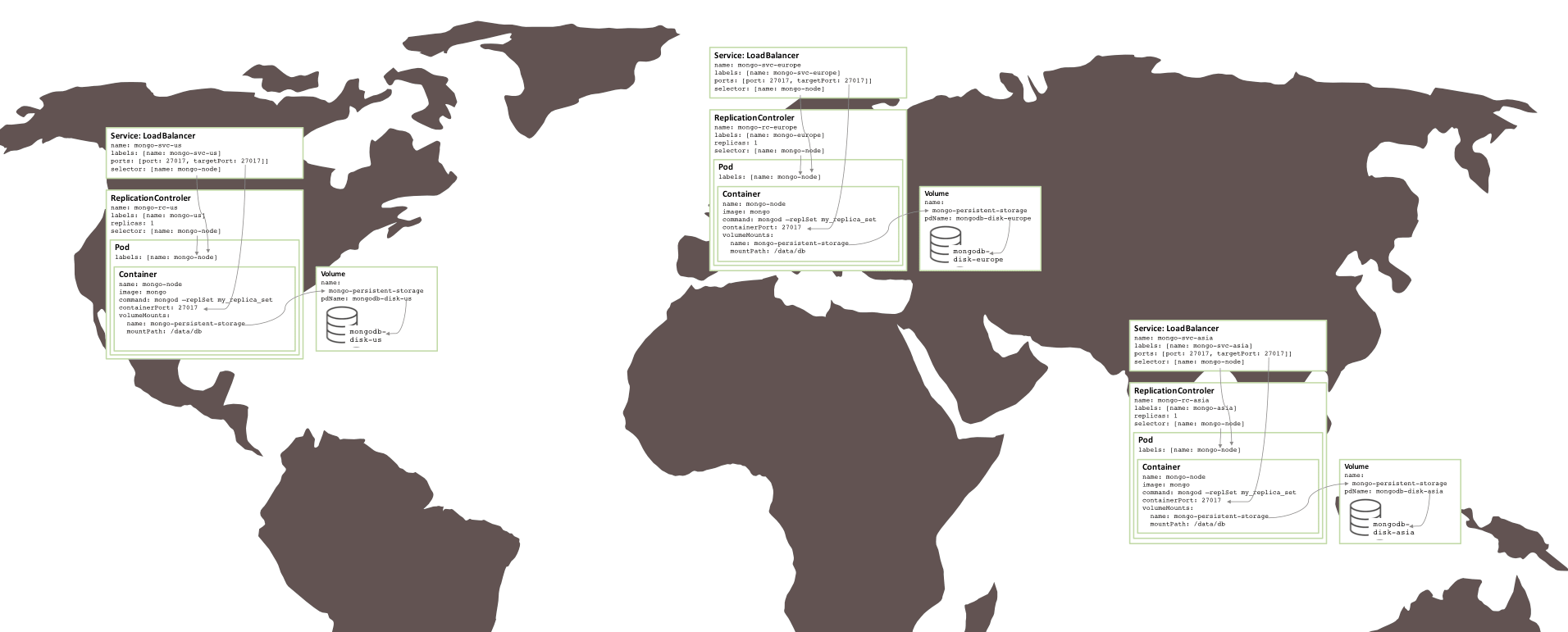
图 5:在多个可用区域上运行的副本集
下一步
要了解有关容器和编排的更多信息 - 所涉及的技术和所提供的业务优势 - 请阅读白皮书《启用微服务:阐述容器和编排》。该文件提供了获取本文中描述的副本集,并在 Google Container Engine 中的 Docker 和 Kubernetes 上运行的完整的说明。
作者简介:
Andrew 是 MongoDB 的产品营销总经理。他在去年夏天离开 Oracle 加入 MongoDB,在 Oracle 他花了 6 年多的时间在产品管理上,专注于高可用性。他可以通过 @andrewmorgan 或者在他的博客(clusterdb.com)评论联系他。
via: https://www.mongodb.com/blog/post/running-mongodb-as-a-microservice-with-docker-and-kubernetes
作者:Andrew Morgan 译者:geekpi 校对:wxy