Reddit 如何实现大规模的帖子浏览计数
我们希望更好地将 Reddit 的规模传达给我们的用户。到目前为止,投票得分和评论数量是特定的帖子活动的主要指标。然而,Reddit 有许多访问者在没有投票或评论的情况下阅读内容。我们希望建立一个能够捕捉到帖子阅读数量的系统。然后将该数量展示给内容创建者和版主,以便他们更好地了解特定帖子上的活动。

在这篇文章中,我们将讨论我们如何大规模地实现计数。
计数方法
对浏览计数有四个主要要求:
- 计数必须是实时的或接近实时的。不是每天或每小时的总量。
- 每个用户在短时间内只能计数一次。
- 显示的数量与实际的误差在百分之几。
- 系统必须能够在生产环境运行,并在事件发生后几秒内处理事件。
满足这四项要求比听起来要复杂得多。为了实时保持准确的计数,我们需要知道某个特定的用户是否曾经访问过这个帖子。要知道这些信息,我们需要存储先前访问过每个帖子的用户组,然后在每次处理对该帖子的新访问时查看该组。这个解决方案的一个原始实现是将这个唯一用户的集合作为散列表存储在内存中,并且以帖子 ID 作为键名。
这种方法适用于浏览量较少的文章,但一旦文章流行,阅读人数迅速增加,这种方法很难扩展。有几个热门的帖子有超过一百万的唯一读者!对于这种帖子,对于内存和 CPU 来说影响都很大,因为要存储所有的 ID,并频繁地查找集合,看看是否有人已经访问过。
由于我们不能提供精确的计数,我们研究了几个不同的基数估计算法。我们考虑了两个非常符合我们期望的选择:
- 线性概率计数方法,非常准确,但要计数的集合越大,则线性地需要更多的内存。
- 基于 HyperLogLog(HLL)的计数方法。HLL 随集合大小 次线性 增长,但不能提供与线性计数器相同的准确度。
要了解 HLL 真正节省的空间大小,看一下这篇文章顶部包括的 r/pics 帖子。它有超过 100 万的唯一用户。如果我们存储 100 万个唯一用户 ID,并且每个用户 ID 是 8 个字节长,那么我们需要 8 兆内存来计算单个帖子的唯一用户数!相比之下,使用 HLL 进行计数会占用更少的内存。每个实现的内存量是不一样的,但是对于这个实现,我们可以使用仅仅 12 千字节的空间计算超过一百万个 ID,这将是原始空间使用量的 0.15%!
(这篇关于高可伸缩性的文章很好地概述了上述两种算法。)
许多 HLL 实现使用了上述两种方法的组合,即对于小集合以线性计数开始,并且一旦大小达到特定点就切换到 HLL。前者通常被称为 “稀疏” HLL 表达,而后者被称为“密集” HLL 表达。混合的方法是非常有利的,因为它可以提供准确的结果,同时保留适度的内存占用量。这个方法在 Google 的 HyperLogLog++ 论文中有更详细的描述。
虽然 HLL 算法是相当标准的,但在我们的实现中我们考虑使用三种变体。请注意,对于内存中的 HLL 实现,我们只关注 Java 和 Scala 实现,因为我们主要在数据工程团队中使用 Java 和 Scala。
- Twitter 的 Algebird 库,用 Scala 实现。Algebird 有很好的使用文档,但是稀疏和密集的 HLL 表达的实现细节不容易理解。
- 在 stream-lib 中的 HyperLogLog++ 的实现,用 Java 实现。stream-lib 中的代码有很好的文档,但是要理解如何正确使用这个库并且调整它以满足我们的需求是有些困难的。
- Redis 的 HLL 实现(我们选择的)。我们认为,Redis 的 HLL 实施方案有很好的文档并且易于配置,所提供的 HLL 相关的 API 易于集成。作为一个额外的好处,使用 Redis 通过将计数应用程序(HLL 计算)的 CPU 和内存密集型部分移出并将其移至专用服务器上,从而缓解了我们的许多性能问题。

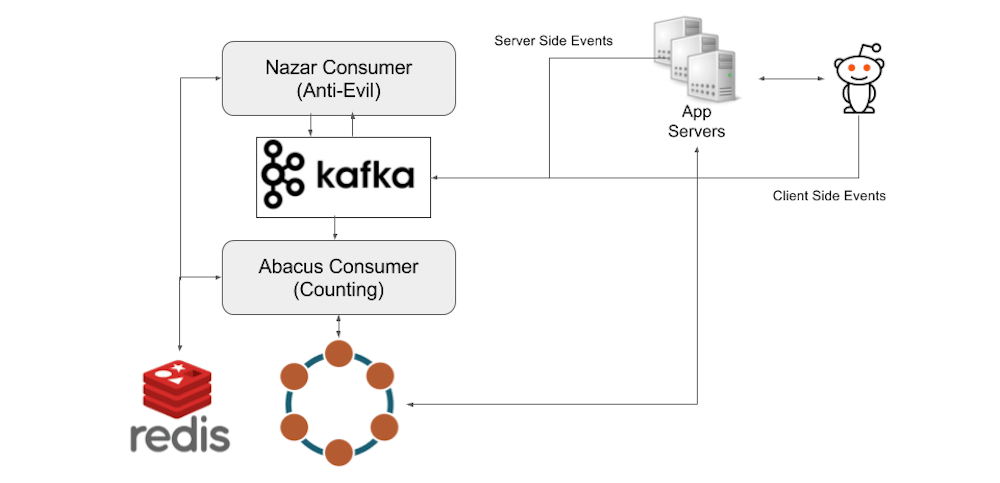
Reddit 的数据管道主要围绕 Apache Kafka。当用户查看帖子时,事件被激发并发送到事件收集器服务器,该服务器批量处理事件并将其保存到 Kafka 中。
从这里,浏览计数系统有两个按顺序运行的组件。我们的计数架构的第一部分是一个名为 Nazar 的 Kafka 消费者,它将读取来自 Kafka 的每个事件,并通过我们编制的一组规则来确定是否应该计算一个事件。我们给它起了这个名字是因为 Nazar 是一个保护你免受邪恶的眼形护身符,Nazar 系统是一个“眼睛”,它可以保护我们免受不良因素的影响。Nazar 使用 Redis 保持状态,并跟踪不应计算浏览的潜在原因。我们可能无法统计事件的一个原因是,由于同一用户在短时间内重复浏览的结果。Nazar 接着将改变事件,添加一个布尔标志表明是否应该被计数,然后再发回 Kafka 事件。
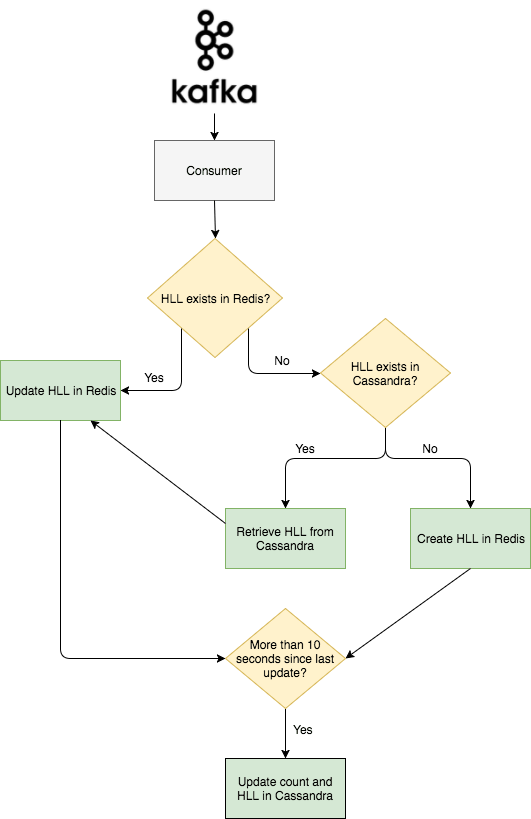
这是这个项目要说的第二部分。我们有第二个叫做 Abacus 的 Kafka 消费者,它实际上对浏览进行计数,并使计数在网站和客户端可见。Abacus 读取 Nazar 输出的 Kafka 事件。接着,根据 Nazar 的决定,它将计算或跳过本次浏览。如果事件被标记为计数,那么 Abacus 首先检查 Redis 中是否存在已经存在与事件对应的帖子的 HLL 计数器。如果计数器已经在 Redis 中,那么 Abacus 向 Redis 发出一个 PFADD 的请求。如果计数器还没有在 Redis 中,那么 Abacus 向 Cassandra 集群发出请求,我们用这个集群来持久化 HLL 计数器和原始计数,并向 Redis 发出一个 SET 请求来添加过滤器。这种情况通常发生在人们查看已经被 Redis 删除的旧帖的时候。
为了保持对可能从 Redis 删除的旧帖子的维护,Abacus 定期将 Redis 的完整 HLL 过滤器以及每个帖子的计数记录到 Cassandra 集群中。 Cassandra 的写入以 10 秒一组分批写入,以避免超载。下面是一个高层的事件流程图。
总结
我们希望浏览量计数器能够更好地帮助内容创作者了解每篇文章的情况,并帮助版主快速确定哪些帖子在其社区拥有大量流量。未来,我们计划利用数据管道的实时潜力向更多的人提供更多有用的反馈。
如果你有兴趣解决这样的问题,请查看我们的职位页面。
via: https://redditblog.com/2017/05/24/view-counting-at-reddit/
作者:Krishnan Chandra 译者:geekpi 校对:wxy