并发服务器(四):libuv

这是并发网络服务器系列文章的第四部分。在这一部分中,我们将使用 libuv 再次重写我们的服务器,并且也会讨论关于使用一个线程池在回调中去处理耗时任务。最终,我们去看一下底层的 libuv,花一点时间去学习如何用异步 API 对文件系统阻塞操作进行封装。
本系列的所有文章:
使用 libuv 抽象出事件驱动循环
在 第三节 中,我们看到了基于 select 和 epoll 的服务器的相似之处,并且,我说过,在它们之间抽象出细微的差别是件很有吸引力的事。许多库已经做到了这些,所以在这一部分中我将去选一个并使用它。我选的这个库是 libuv,它最初设计用于 Node.js 底层的可移植平台层,并且,后来发现在其它的项目中也有使用。libuv 是用 C 写的,因此,它具有很高的可移植性,非常适用嵌入到像 JavaScript 和 Python 这样的高级语言中。
虽然 libuv 为了抽象出底层平台细节已经变成了一个相当大的框架,但它仍然是以 事件循环 思想为中心的。在我们第三部分的事件驱动服务器中,事件循环是显式定义在 main 函数中的;当使用 libuv 时,该循环通常隐藏在库自身中,而用户代码仅需要注册事件句柄(作为一个回调函数)和运行这个循环。此外,libuv 会在给定的平台上使用更快的事件循环实现,对于 Linux 它是 epoll,等等。
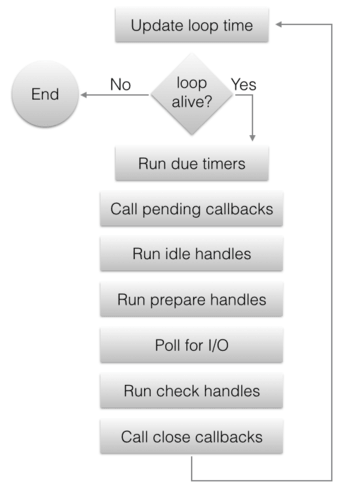
libuv 支持多路事件循环,因此事件循环在库中是非常重要的;它有一个句柄 —— uv_loop_t,以及创建/杀死/启动/停止循环的函数。也就是说,在这篇文章中,我将仅需要使用 “默认的” 循环,libuv 可通过 uv_default_loop() 提供它;多路循环大多用于多线程事件驱动的服务器,这是一个更高级别的话题,我将留在这一系列文章的以后部分。
使用 libuv 的并发服务器
为了对 libuv 有一个更深的印象,让我们跳转到我们的可靠协议的服务器,它通过我们的这个系列已经有了一个强大的重新实现。这个服务器的结构与第三部分中的基于 select 和 epoll 的服务器有一些相似之处,因为,它也依赖回调。完整的 示例代码在这里;我们开始设置这个服务器的套接字绑定到一个本地端口:
int portnum = 9090;
if (argc >= 2) {
portnum = atoi(argv[1]);
}
printf("Serving on port %d\n", portnum);
int rc;
uv_tcp_t server_stream;
if ((rc = uv_tcp_init(uv_default_loop(), &server_stream)) < 0) {
die("uv_tcp_init failed: %s", uv_strerror(rc));
}
struct sockaddr_in server_address;
if ((rc = uv_ip4_addr("0.0.0.0", portnum, &server_address)) < 0) {
die("uv_ip4_addr failed: %s", uv_strerror(rc));
}
if ((rc = uv_tcp_bind(&server_stream, (const struct sockaddr*)&server_address, 0)) < 0) {
die("uv_tcp_bind failed: %s", uv_strerror(rc));
}
除了它被封装进 libuv API 中之外,你看到的是一个相当标准的套接字。在它的返回中,我们取得了一个可工作于任何 libuv 支持的平台上的可移植接口。
这些代码也展示了很认真负责的错误处理;多数的 libuv 函数返回一个整数状态,返回一个负数意味着出现了一个错误。在我们的服务器中,我们把这些错误看做致命问题进行处理,但也可以设想一个更优雅的错误恢复。
现在,那个套接字已经绑定,是时候去监听它了。这里我们运行首个回调注册:
// Listen on the socket for new peers to connect. When a new peer connects,
// the on_peer_connected callback will be invoked.
if ((rc = uv_listen((uv_stream_t*)&server_stream, N_BACKLOG, on_peer_connected)) < 0) {
die("uv_listen failed: %s", uv_strerror(rc));
}
uv_listen 注册一个事件回调,当新的对端连接到这个套接字时将会调用事件循环。我们的回调在这里被称为 on_peer_connected,我们一会儿将去查看它。
最终,main 运行这个 libuv 循环,直到它被停止(uv_run 仅在循环被停止或者发生错误时返回)。
// Run the libuv event loop.
uv_run(uv_default_loop(), UV_RUN_DEFAULT);
// If uv_run returned, close the default loop before exiting.
return uv_loop_close(uv_default_loop());
注意,在运行事件循环之前,只有一个回调是通过 main 注册的;我们稍后将看到怎么去添加更多的回调。在事件循环的整个运行过程中,添加和删除回调并不是一个问题 —— 事实上,大多数服务器就是这么写的。
这是一个 on_peer_connected,它处理到服务器的新的客户端连接:
void on_peer_connected(uv_stream_t* server_stream, int status) {
if (status < 0) {
fprintf(stderr, "Peer connection error: %s\n", uv_strerror(status));
return;
}
// client will represent this peer; it's allocated on the heap and only
// released when the client disconnects. The client holds a pointer to
// peer_state_t in its data field; this peer state tracks the protocol state
// with this client throughout interaction.
uv_tcp_t* client = (uv_tcp_t*)xmalloc(sizeof(*client));
int rc;
if ((rc = uv_tcp_init(uv_default_loop(), client)) < 0) {
die("uv_tcp_init failed: %s", uv_strerror(rc));
}
client->data = NULL;
if (uv_accept(server_stream, (uv_stream_t*)client) == 0) {
struct sockaddr_storage peername;
int namelen = sizeof(peername);
if ((rc = uv_tcp_getpeername(client, (struct sockaddr*)&peername,
&namelen)) < 0) {
die("uv_tcp_getpeername failed: %s", uv_strerror(rc));
}
report_peer_connected((const struct sockaddr_in*)&peername, namelen);
// Initialize the peer state for a new client: we start by sending the peer
// the initial '*' ack.
peer_state_t* peerstate = (peer_state_t*)xmalloc(sizeof(*peerstate));
peerstate->state = INITIAL_ACK;
peerstate->sendbuf[0] = '*';
peerstate->sendbuf_end = 1;
peerstate->client = client;
client->data = peerstate;
// Enqueue the write request to send the ack; when it's done,
// on_wrote_init_ack will be called. The peer state is passed to the write
// request via the data pointer; the write request does not own this peer
// state - it's owned by the client handle.
uv_buf_t writebuf = uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
uv_write_t* req = (uv_write_t*)xmalloc(sizeof(*req));
req->data = peerstate;
if ((rc = uv_write(req, (uv_stream_t*)client, &writebuf, 1,
on_wrote_init_ack)) < 0) {
die("uv_write failed: %s", uv_strerror(rc));
}
} else {
uv_close((uv_handle_t*)client, on_client_closed);
}
}
这些代码都有很好的注释,但是,这里有一些重要的 libuv 语法我想去强调一下:
- 传入自定义数据到回调中:因为 C 语言还没有闭包,这可能是个挑战,libuv 在它的所有的处理类型中有一个
void* data字段;这些字段可以被用于传递用户数据。例如,注意client->data是如何指向到一个peer_state_t结构上,以便于uv_write和uv_read_start注册的回调可以知道它们正在处理的是哪个客户端的数据。 - 内存管理:在带有垃圾回收的语言中进行事件驱动编程是非常容易的,因为,回调通常运行在一个与它们注册的地方完全不同的栈帧中,使得基于栈的内存管理很困难。它总是需要传递堆分配的数据到 libuv 回调中(当所有回调运行时,除了
main,其它的都运行在栈上),并且,为了避免泄漏,许多情况下都要求这些数据去安全释放(free())。这些都是些需要实践的内容 注1 。
这个服务器上对端的状态如下:
typedef struct {
ProcessingState state;
char sendbuf[SENDBUF_SIZE];
int sendbuf_end;
uv_tcp_t* client;
} peer_state_t;
它与第三部分中的状态非常类似;我们不再需要 sendptr,因为,在调用 “done writing” 回调之前,uv_write 将确保发送它提供的整个缓冲。我们也为其它的回调使用保持了一个到客户端的指针。这里是 on_wrote_init_ack:
void on_wrote_init_ack(uv_write_t* req, int status) {
if (status) {
die("Write error: %s\n", uv_strerror(status));
}
peer_state_t* peerstate = (peer_state_t*)req->data;
// Flip the peer state to WAIT_FOR_MSG, and start listening for incoming data
// from this peer.
peerstate->state = WAIT_FOR_MSG;
peerstate->sendbuf_end = 0;
int rc;
if ((rc = uv_read_start((uv_stream_t*)peerstate->client, on_alloc_buffer,
on_peer_read)) < 0) {
die("uv_read_start failed: %s", uv_strerror(rc));
}
// Note: the write request doesn't own the peer state, hence we only free the
// request itself, not the state.
free(req);
}
然后,我们确信知道了这个初始的 '*' 已经被发送到对端,我们通过调用 uv_read_start 去监听从这个对端来的入站数据,它注册一个将被事件循环调用的回调(on_peer_read),不论什么时候,事件循环都在套接字上接收来自客户端的调用:
void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
if (nread < 0) {
if (nread != uv_eof) {
fprintf(stderr, "read error: %s\n", uv_strerror(nread));
}
uv_close((uv_handle_t*)client, on_client_closed);
} else if (nread == 0) {
// from the documentation of uv_read_cb: nread might be 0, which does not
// indicate an error or eof. this is equivalent to eagain or ewouldblock
// under read(2).
} else {
// nread > 0
assert(buf->len >= nread);
peer_state_t* peerstate = (peer_state_t*)client->data;
if (peerstate->state == initial_ack) {
// if the initial ack hasn't been sent for some reason, ignore whatever
// the client sends in.
free(buf->base);
return;
}
// run the protocol state machine.
for (int i = 0; i < nread; ++i) {
switch (peerstate->state) {
case initial_ack:
assert(0 && "can't reach here");
break;
case wait_for_msg:
if (buf->base[i] == '^') {
peerstate->state = in_msg;
}
break;
case in_msg:
if (buf->base[i] == '$') {
peerstate->state = wait_for_msg;
} else {
assert(peerstate->sendbuf_end < sendbuf_size);
peerstate->sendbuf[peerstate->sendbuf_end++] = buf->base[i] + 1;
}
break;
}
}
if (peerstate->sendbuf_end > 0) {
// we have data to send. the write buffer will point to the buffer stored
// in the peer state for this client.
uv_buf_t writebuf =
uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
uv_write_t* writereq = (uv_write_t*)xmalloc(sizeof(*writereq));
writereq->data = peerstate;
int rc;
if ((rc = uv_write(writereq, (uv_stream_t*)client, &writebuf, 1,
on_wrote_buf)) < 0) {
die("uv_write failed: %s", uv_strerror(rc));
}
}
}
free(buf->base);
}
这个服务器的运行时行为非常类似于第三部分的事件驱动服务器:所有的客户端都在一个单个的线程中并发处理。并且类似的,一些特定的行为必须在服务器代码中维护:服务器的逻辑实现为一个集成的回调,并且长周期运行是禁止的,因为它会阻塞事件循环。这一点也很类似。让我们进一步探索这个问题。
在事件驱动循环中的长周期运行的操作
单线程的事件驱动代码使它先天就容易受到一些常见问题的影响:长周期运行的代码会阻塞整个循环。参见如下的程序:
void on_timer(uv_timer_t* timer) {
uint64_t timestamp = uv_hrtime();
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
// "Work"
if (random() % 5 == 0) {
printf("Sleeping...\n");
sleep(3);
}
}
int main(int argc, const char** argv) {
uv_timer_t timer;
uv_timer_init(uv_default_loop(), &timer);
uv_timer_start(&timer, on_timer, 0, 1000);
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
}
它用一个单个注册的回调运行一个 libuv 事件循环:on_timer,它被每秒钟循环调用一次。回调报告一个时间戳,并且,偶尔通过睡眠 3 秒去模拟一个长周期运行。这是运行示例:
$ ./uv-timer-sleep-demo
on_timer [4840 ms]
on_timer [5842 ms]
on_timer [6843 ms]
on_timer [7844 ms]
Sleeping...
on_timer [11845 ms]
on_timer [12846 ms]
Sleeping...
on_timer [16847 ms]
on_timer [17849 ms]
on_timer [18850 ms]
...
on_timer 忠实地每秒执行一次,直到随机出现的睡眠为止。在那个时间点,on_timer 不再被调用,直到睡眠时间结束;事实上,没有其它的回调 会在这个时间帧中被调用。这个睡眠调用阻塞了当前线程,它正是被调用的线程,并且也是事件循环使用的线程。当这个线程被阻塞后,事件循环也被阻塞。
这个示例演示了在事件驱动的调用中为什么回调不能被阻塞是多少的重要。并且,同样适用于 Node.js 服务器、客户端侧的 Javascript、大多数的 GUI 编程框架、以及许多其它的异步编程模型。
但是,有时候运行耗时的任务是不可避免的。并不是所有任务都有一个异步 API;例如,我们可能使用一些仅有同步 API 的库去处理,或者,正在执行一个可能的长周期计算。我们如何用事件驱动编程去结合这些代码?线程可以帮到你!
“转换” 阻塞调用为异步调用的线程
一个线程池可以用于转换阻塞调用为异步调用,通过与事件循环并行运行,并且当任务完成时去由它去公布事件。以阻塞函数 do_work() 为例,这里介绍了它是怎么运行的:
- 不在一个回调中直接调用
do_work(),而是将它打包进一个 “任务”,让线程池去运行这个任务。当任务完成时,我们也为循环去调用它注册一个回调;我们称它为on_work_done()。 - 在这个时间点,我们的回调就可以返回了,而事件循环保持运行;在同一时间点,线程池中的有一个线程运行这个任务。
- 一旦任务运行完成,通知主线程(指正在运行事件循环的线程),并且事件循环调用
on_work_done()。
让我们看一下,使用 libuv 的工作调度 API,是怎么去解决我们前面的计时器/睡眠示例中展示的问题的:
void on_after_work(uv_work_t* req, int status) {
free(req);
}
void on_work(uv_work_t* req) {
// "Work"
if (random() % 5 == 0) {
printf("Sleeping...\n");
sleep(3);
}
}
void on_timer(uv_timer_t* timer) {
uint64_t timestamp = uv_hrtime();
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
uv_work_t* work_req = (uv_work_t*)malloc(sizeof(*work_req));
uv_queue_work(uv_default_loop(), work_req, on_work, on_after_work);
}
int main(int argc, const char** argv) {
uv_timer_t timer;
uv_timer_init(uv_default_loop(), &timer);
uv_timer_start(&timer, on_timer, 0, 1000);
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
}
通过一个 work_req 注2 类型的句柄,我们进入一个任务队列,代替在 on_timer 上直接调用 sleep,这个函数在任务中(on_work)运行,并且,一旦任务完成(on_after_work),这个函数被调用一次。on_work 是指 “work”(阻塞中的/耗时的操作)进行的地方。注意在这两个回调传递到 uv_queue_work 时的一个关键区别:on_work 运行在线程池中,而 on_after_work 运行在事件循环中的主线程上 —— 就好像是其它的回调一样。
让我们看一下这种方式的运行:
$ ./uv-timer-work-demo
on_timer [89571 ms]
on_timer [90572 ms]
on_timer [91573 ms]
on_timer [92575 ms]
Sleeping...
on_timer [93576 ms]
on_timer [94577 ms]
Sleeping...
on_timer [95577 ms]
on_timer [96578 ms]
on_timer [97578 ms]
...
即便在 sleep 函数被调用时,定时器也每秒钟滴答一下,睡眠现在运行在一个单独的线程中,并且不会阻塞事件循环。
一个用于练习的素数测试服务器
因为通过睡眠去模拟工作并不是件让人兴奋的事,我有一个事先准备好的更综合的一个示例 —— 一个基于套接字接受来自客户端的数字的服务器,检查这个数字是否是素数,然后去返回一个 “prime" 或者 “composite”。完整的 服务器代码在这里 —— 我不在这里粘贴了,因为它太长了,更希望读者在一些自己的练习中去体会它。
这个服务器使用了一个原生的素数测试算法,因此,对于大的素数可能花很长时间才返回一个回答。在我的机器中,对于 2305843009213693951,它花了 ~5 秒钟去计算,但是,你的方法可能不同。
练习 1:服务器有一个设置(通过一个名为 MODE 的环境变量)要么在套接字回调(意味着在主线程上)中运行素数测试,要么在 libuv 工作队列中。当多个客户端同时连接时,使用这个设置来观察服务器的行为。当它计算一个大的任务时,在阻塞模式中,服务器将不回复其它客户端,而在非阻塞模式中,它会回复。
练习 2:libuv 有一个缺省大小的线程池,并且线程池的大小可以通过环境变量配置。你可以通过使用多个客户端去实验找出它的缺省值是多少?找到线程池缺省值后,使用不同的设置去看一下,在重负载下怎么去影响服务器的响应能力。
在非阻塞文件系统中使用工作队列
对于只是呆板的演示和 CPU 密集型的计算来说,将可能的阻塞操作委托给一个线程池并不是明智的;libuv 在它的文件系统 API 中本身就大量使用了这种能力。通过这种方式,libuv 使用一个异步 API,以一个轻便的方式显示出它强大的文件系统的处理能力。
让我们使用 uv_fs_read(),例如,这个函数从一个文件中(表示为一个 uv_fs_t 句柄)读取一个文件到一个缓冲中 注3,并且当读取完成后调用一个回调。换句话说, uv_fs_read() 总是立即返回,即使是文件在一个类似 NFS 的系统上,而数据到达缓冲区可能需要一些时间。换句话说,这个 API 与这种方式中其它的 libuv API 是异步的。这是怎么工作的呢?
在这一点上,我们看一下 libuv 的底层;内部实际上非常简单,并且它是一个很好的练习。作为一个可移植的库,libuv 对于 Windows 和 Unix 系统在它的许多函数上有不同的实现。我们去看一下在 libuv 源树中的 src/unix/fs.c。
这是 uv_fs_read 的代码:
int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
uv_file file,
const uv_buf_t bufs[],
unsigned int nbufs,
int64_t off,
uv_fs_cb cb) {
if (bufs == NULL || nbufs == 0)
return -EINVAL;
INIT(READ);
req->file = file;
req->nbufs = nbufs;
req->bufs = req->bufsml;
if (nbufs > ARRAY_SIZE(req->bufsml))
req->bufs = uv__malloc(nbufs * sizeof(*bufs));
if (req->bufs == NULL) {
if (cb != NULL)
uv__req_unregister(loop, req);
return -ENOMEM;
}
memcpy(req->bufs, bufs, nbufs * sizeof(*bufs));
req->off = off;
POST;
}
第一次看可能觉得很困难,因为它延缓真实的工作到 INIT 和 POST 宏中,以及为 POST 设置了一些本地变量。这样做可以避免了文件中的许多重复代码。
这是 INIT 宏:
#define INIT(subtype) \
do { \
req->type = UV_FS; \
if (cb != NULL) \
uv__req_init(loop, req, UV_FS); \
req->fs_type = UV_FS_ ## subtype; \
req->result = 0; \
req->ptr = NULL; \
req->loop = loop; \
req->path = NULL; \
req->new_path = NULL; \
req->cb = cb; \
} \
while (0)
它设置了请求,并且更重要的是,设置 req->fs_type 域为真实的 FS 请求类型。因为 uv_fs_read 调用 INIT(READ),它意味着 req->fs_type 被分配一个常数 UV_FS_READ。
这是 POST 宏:
#define POST \
do { \
if (cb != NULL) { \
uv__work_submit(loop, &req->work_req, uv__fs_work, uv__fs_done); \
return 0; \
} \
else { \
uv__fs_work(&req->work_req); \
return req->result; \
} \
} \
while (0)
它做什么取决于回调是否为 NULL。在 libuv 文件系统 API 中,一个 NULL 回调意味着我们真实地希望去执行一个 同步 操作。在这种情况下,POST 直接调用 uv__fs_work(我们需要了解一下这个函数的功能),而对于一个非 NULL 回调,它把 uv__fs_work 作为一个工作项提交到工作队列(指的是线程池),然后,注册 uv__fs_done 作为回调;该函数执行一些登记并调用用户提供的回调。
如果我们去看 uv__fs_work 的代码,我们将看到它使用很多宏按照需求将工作分发到实际的文件系统调用。在我们的案例中,对于 UV_FS_READ 这个调用将被 uv__fs_read 生成,它(最终)使用普通的 POSIX API 去读取。这个函数可以在一个 阻塞 方式中很安全地实现。因为,它通过异步 API 调用时被置于一个线程池中。
在 Node.js 中,fs.readFile 函数是映射到 uv_fs_read 上。因此,可以在一个非阻塞模式中读取文件,甚至是当底层文件系统 API 是阻塞方式时。
- 注1: 为确保服务器不泄露内存,我在一个启用泄露检查的 Valgrind 中运行它。因为服务器经常是被设计为永久运行,这是一个挑战;为克服这个问题,我在服务器上添加了一个 “kill 开关” —— 一个从客户端接收的特定序列,以使它可以停止事件循环并退出。这个代码在
theon_wrote_buf句柄中。 - 注2: 在这里我们不过多地使用
work_req;讨论的素数测试服务器接下来将展示怎么被用于去传递上下文信息到回调中。 - 注3:
uv_fs_read()提供了一个类似于preadvLinux 系统调用的通用 API:它使用多缓冲区用于排序,并且支持一个到文件中的偏移。基于我们讨论的目的可以忽略这些特性。
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
作者:Eli Bendersky 译者:qhwdw 校对:wxy