极致技术探索:显卡工作原理

自从 3dfx 推出最初的 Voodoo 加速器以来,不起眼的显卡对你的 PC 是否可以玩游戏起到决定性作用,PC 上任何其它设备都无法与其相比。其它组件当然也很重要,但对于一个拥有 32GB 内存、价值 500 美金的 CPU 和 基于 PCIe 的存储设备的高端 PC,如果使用 10 年前的显卡,都无法以最高分辨率和细节质量运行当前 最高品质的游戏 ,会发生卡顿甚至无响应。显卡(也常被称为 GPU,即 图形处理单元 ),对游戏性能影响极大,我们反复强调这一点;但我们通常并不会深入了解显卡的工作原理。
出于实际考虑,本文将概述 GPU 的上层功能特性,内容包括 AMD 显卡、Nvidia 显卡、Intel 集成显卡以及 Intel 后续可能发布的独立显卡之间共同的部分。也应该适用于 Apple、Imagination Technologies、Qualcomm、ARM 和其它显卡生产商发布的移动平台 GPU。
我们为何不使用 CPU 进行渲染?
我要说明的第一点是我们为何不直接使用 CPU 完成游戏中的渲染工作。坦率的说,在理论上你确实可以直接使用 CPU 完成 渲染 工作。在显卡没有广泛普及之前,早期的 3D 游戏就是完全基于 CPU 运行的,例如 《 地下创世纪 (下文中简称 UU)。UU 是一个很特别的例子,原因如下:与《 毁灭战士 相比,UU 具有一个更高级的渲染引擎,全面支持“向上或向下看”以及一些在当时比较高级的特性,例如 纹理映射 。但为支持这些高级特性,需要付出高昂的代价,很少有人可以拥有真正能运行起 UU 的 PC。
地下创世纪,图片来自 GOG
对于早期的 3D 游戏,包括《 半条命 》和《 雷神之锤 2 》在内的很多游戏,内部包含一个软件渲染器,让没有 3D 加速器的玩家也可以玩游戏。但现代游戏都弃用了这种方式,原因很简单:CPU 是设计用于通用任务的微处理器,意味着缺少 GPU 提供的 专用硬件 和 功能 。对于 18 年前使用软件渲染的那些游戏,当代 CPU 可以轻松胜任;但对于当代最高品质的游戏,除非明显降低 景象质量 、分辨率和各种虚拟特效,否则现有的 CPU 都无法胜任。
什么是 GPU ?
GPU 是一种包含一系列专用硬件特性的设备,其中这些特性可以让各种 3D 引擎更好地执行代码,包括 形状构建 ,纹理映射, 访存 和 着色器 等。3D 引擎的功能特性影响着设计者如何设计 GPU。可能有人还记得,AMD HD5000 系列使用 VLIW5 架构 ;但在更高端的 HD 6000 系列中使用了 VLIW4 架构。通过 GCN (LCTT 译注:GCN 是 Graphics Core Next 的缩写,字面意思是“下一代图形核心”,既是若干代微体系结构的代号,也是指令集的名称),AMD 改变了并行化的实现方法,提高了每个时钟周期的有效性能。

“GPU 革命”的前两块奠基石属于 AMD 和 NV;而“第三个时代”则独属于 AMD。
Nvidia 在发布首款 GeForce 256 时(大致对应 Microsoft 推出 DirectX7 的时间点)提出了 GPU 这个术语,这款 GPU 支持在硬件上执行转换和 光照计算 。将专用功能直接集成到硬件中是早期 GPU 的显著技术特点。很多专用功能还在(以一种极为不同的方式)使用,毕竟对于特定类型的工作任务,使用 片上 专用计算资源明显比使用一组 可编程单元 要更加高效和快速。
GPU 和 CPU 的核心有很多差异,但我们可以按如下方式比较其上层特性。CPU 一般被设计成尽可能快速和高效的执行单线程代码。虽然 同时多线程 (SMT)或 超线程 (HT)在这方面有所改进,但我们实际上通过堆叠众多高效率的单线程核心来扩展多线程性能。AMD 的 32 核心/64 线程 Epyc CPU 已经是我们能买到的核心数最多的 CPU;相比而言,Nvidia 最低端的 Pascal GPU 都拥有 384 个核心。但相比 CPU 的核心,GPU 所谓的核心是处理能力低得多的的处理单元。
注意: 简单比较 GPU 核心数,无法比较或评估 AMD 与 Nvidia 的相对游戏性能。在同样 GPU 系列(例如 Nvidia 的 GeForce GTX 10 系列,或 AMD 的 RX 4xx 或 5xx 系列)的情况下,更高的 GPU 核心数往往意味着更高的性能。
你无法只根据核心数比较不同供应商或核心系列的 GPU 之间的性能,这是因为不同的架构对应的效率各不相同。与 CPU 不同,GPU 被设计用于并行计算。AMD 和 Nvidia 在结构上都划分为计算资源 块 。Nvidia 将这些块称之为 流处理器 (SM),而 AMD 则称之为 计算单元 (CU)。
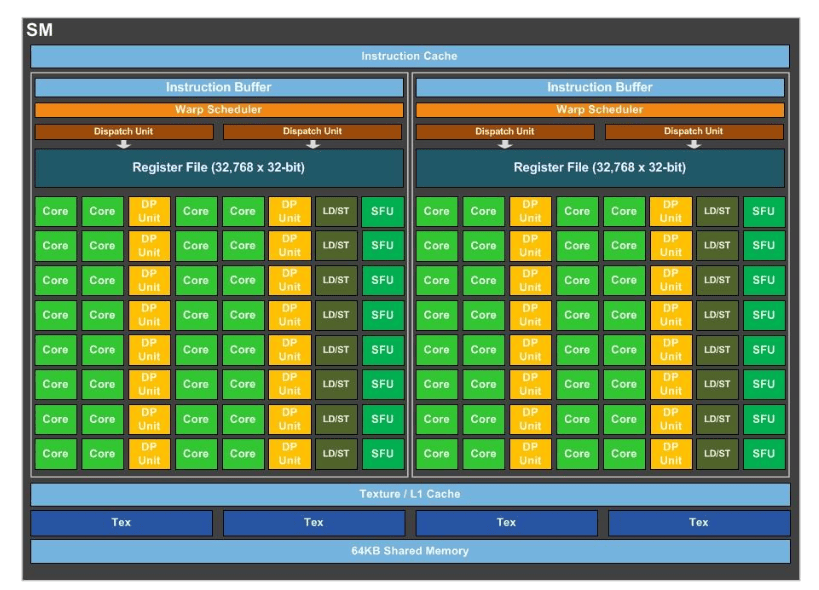
一个 Pascal 流处理器(SM)。
每个块都包含如下组件:一组核心、一个 调度器 、一个 寄存器文件 、指令缓存、纹理和 L1 缓存以及纹理 映射单元 。SM/CU 可以被认为是 GPU 中最小的可工作块。SM/CU 没有涵盖全部的功能单元,例如视频解码引擎,实际在屏幕绘图所需的渲染输出,以及与 板载 显存 (VRAM)通信相关的 内存接口 都不在 SM/CU 的范围内;但当 AMD 提到一个 APU 拥有 8 或 11 个 Vega 计算单元时,所指的是(等价的) 硅晶块 数目。如果你查看任意一款 GPU 的模块设计图,你会发现图中 SM/CU 是反复出现很多次的部分。

这是 Pascal 的全平面图
GPU 中的 SM/CU 数目越多,每个时钟周期内可以并行完成的工作也越多。渲染是一种通常被认为是“高度并行”的计算问题,意味着随着核心数增加带来的可扩展性很高。
当我们讨论 GPU 设计时,我们通常会使用一种形如 4096:160:64 的格式,其中第一个数字代表核心数。在核心系列(如 GTX970/GTX 980/GTX 980 Ti,如 RX 560/RX 580 等等)一致的情况下,核心数越高,GPU 也就相对更快。
纹理映射和渲染输出
GPU 的另外两个主要组件是纹理映射单元和渲染输出。设计中的纹理映射单元数目决定了最大的 纹素 输出以及可以多快的处理并将纹理映射到对象上。早期的 3D 游戏很少用到纹理,这是因为绘制 3D 多边形形状的工作有较大的难度。纹理其实并不是 3D 游戏必须的,但不使用纹理的现代游戏屈指可数。
GPU 中的纹理映射单元数目用 4096:160:64 指标中的第二个数字表示。AMD、Nvidia 和 Intel 一般都等比例变更指标中的数字。换句话说,如果你找到一个指标为 4096:160:64 的 GPU,同系列中不会出现指标为 4096:320:64 的 GPU。纹理映射绝对有可能成为游戏的瓶颈,但产品系列中次高级别的 GPU 往往提供更多的核心和纹理映射单元(是否拥有更高的渲染输出单元取决于 GPU 系列和显卡的指标)。
渲染输出单元 (ROP),有时也叫做 光栅操作管道 是 GPU 输出汇集成图像的场所,图像最终会在显示器或电视上呈现。渲染输出单元的数目乘以 GPU 的时钟频率决定了 像素填充速率 。渲染输出单元数目越多意味着可以同时输出的像素越多。渲染输出单元还处理 抗锯齿 ,启用抗锯齿(尤其是 超级采样 抗锯齿)会导致游戏填充速率受限。
显存带宽与显存容量
我们最后要讨论的是 显存带宽 和 显存容量 。显存带宽是指一秒时间内可以从 GPU 专用的显存缓冲区内拷贝进或拷贝出多少数据。很多高级视觉特效(以及更常见的高分辨率)需要更高的显存带宽,以便保证足够的 帧率 ,因为需要拷贝进和拷贝出 GPU 核心的数据总量增大了。
在某些情况下,显存带宽不足会成为 GPU 的显著瓶颈。以 Ryzen 5 2400G 为例的 AMD APU 就是严重带宽受限的,以至于提高 DDR4 的时钟频率可以显著提高整体性能。导致瓶颈的显存带宽阈值,也与游戏引擎和游戏使用的分辨率相关。
板载内存大小也是 GPU 的重要指标。如果按指定细节级别或分辨率运行所需的显存量超过了可用的资源量,游戏通常仍可以运行,但会使用 CPU 的主存来存储额外的纹理数据;而从 DRAM 中提取数据比从板载显存中提取数据要慢得多。这会导致游戏在板载的快速访问内存池和系统内存中共同提取数据时出现明显的卡顿。
有一点我们需要留意,GPU 生产厂家通常为一款低端或中端 GPU 配置比通常更大的显存,这是他们为产品提价的一种常用手段。很难说大显存是否更具有吸引力,毕竟需要具体问题具体分析。大多数情况下,用更高的价格购买一款仅是显存更高的显卡是不划算的。经验规律告诉我们,低端显卡遇到显存瓶颈之前就会碰到其它瓶颈。如果存在疑问,可以查看相关评论,例如 4G 版本或其它数目的版本是否性能超过 2G 版本。更多情况下,如果其它指标都相同,购买大显存版本并不值得。
查看我们的极致技术探索系列,深入了解更多当前最热的技术话题。
via: https://www.extremetech.com/gaming/269335-how-graphics-cards-work
作者:Joel Hruska 选题:lujun9972 译者:pinewall 校对:wxy